In the enterprise space, integration problems abound. IT must connect numerous legacy systems in new applications to adjust to the changing needs of the business. Technologies to achieve such integrations include SOAP based Web Services (WS-*) and binary protocols such as CORBA and RMI. This blog entry discusses a different approach - integration using lightweight REST APIs.
To illustrate the concept, a demo has been created showing how to combine data from Oracle's WebLogic Portal product with data from Oracle Database. This demo is accomplished using RESTful APIs as the data transport mechanism, and is orchestrated by a third party data integration product called SnapLogic. This demo was showcased at a REST Symposium I organized for Oracle employees in July, which featured speakers from Oracle, SnapLogic and Yahoo! (see below for details).
What is REST?
REST is an acronym for REpresentational State Transfer, and was coined by Roy Fielding in his PhD thesis published in 2000. It is not a technology, a standard, or a product. REST is an architectural pattern that describes the underlying architecture of the World Wide Web and how it came to be such a massively scalable computer application. The WWW is known to have the following qualities:
- Highly scalable - millions of websites
- Fault tolerant - at any given time, many websites are offline, but the web continues to work
- Performance- HTTP allows for intermediaries to help improve performance via caching
- Interoperable - nearly every computing platform has a browser, and websites are written in a myriad of languages
- Distributed - websites and clients span the globe
- Self describing - there is no user manual required for users to navigate the WWW
Aren't the above qualities desired for any enterprise systems as well? The power of REST lies in the idea that the same fundamentals that work so well for the WWW can also work with great success within the enterprise.
There are plenty of resources on the web that explain the principles of REST, and so I have no intention of duplicating that material. In essence REST describes an architecture in which:
- Application resources (objects, in the OO world) are exposed as URIs
- HTTP requests are used to retrieve and update data on the server
- The HTTP requests utilize the standard HTTP verbs (GET, POST, PUT, DELETE) to define the API operations, helping client developers by providing a consistent interaction model
An example is the following:
- A client issues a request to the following URI: http://wlp.bea.com/dvt/api/content/autos.jsp
- The server response contains a list of automobiles, described in a format such as XML
- The client consumes the XML document and outputs the entries that match the user's criteria
This pattern is seen most often with Rich Internet Applications (RIA), where the client is a browser and the API is being invoked via Ajax (more precisely, the JavaScript XmlHttpRequest facility). While this is a very powerful use of RESTful APIs and is alone enough to justify the creation of RESTful APIs, this use case is not the focus of this blog entry. I would encourage you to research Ajax application development for more background.
Instead, we will look more closely at how RESTful APIs can also make data integration easy.
RESTful Integration in Concept
RESTful APIs expose data in a way that is easily consumed. Invoking the API is as easy as issuing an HTTP request, which is possible to do from almost any programming language/platform. While enterprise data integration can be implemented using a wide variety of technologies, the purpose of this blog entry is to show how it can be done with RESTful APIs.
As stated in the preamble, there are non-RESTful approaches to solving this problem. A SOAP based solution could be implemented and for some cases is the preferred approach. If your use case requires the support of the WS-* family of standards, then WS-* is the way to go. What this example shows is that REST offers an alternative and is appealing in its simplicity.
Instead of discussing the theory, it is more useful to look at a working example.
Example: Oracle WebLogic Portal + Oracle Database + SnapLogic + REST
Consider the following example:
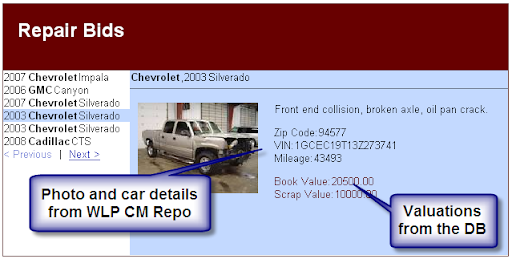
- An insurance company is using the Content Management capabilities of Oracle WebLogic Portal to store auto claims. Each claim contains a photo of the damaged vehicle, and some data about that vehicle such as make, model, year and a description of the damage.
- The insurance company also has a Oracle Database that is populated with industry data regarding the fair market value of the cars, and the salvage value. These values are specific to the make, model and year.
- The insurance company wishes to put the repair of the damaged vehicles out to bid to a community of auto repair shops. The intent is to allow shops to bid on the vehicles they are willing to repair using the industry data and the information from the claim.
The insurance company decides to use a quick and lightweight approach to build a data mashup with a web UI. The implementation is achieved using RESTful APIs, and orchestrated using a product called SnapLogic. SnapLogic is an open source server that provides:
- Many pre-built connectors to expose native data sources as RESTful APIs (e.g. database, spreadsheet, XML)
- Sophisticated data manipulation capabilities, such as joins, filtering, sorting, and computations
- A variety of output formats for the completed RESTful feed
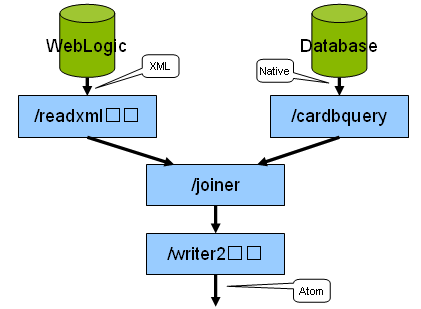
The data integration demo was implemented as follows:
- A RESTful API is configured for the WebLogic Portal (WLP) Content Management system. In this example, the RESTful API was custom built as a JSP, but this capability will come pre-built in a future version of WLP.
- The Oracle Database schema is exposed as a RESTful data API using an out of the box Database Reader component of the SnapLogic server.
- The two data sources are joined using a SnapLogic pipeline. The pipeline reads the claims from WLP CM and the industry data from the database using the RESTful APIs.
- The joined data is converted into an ATOM syndication feed via the SnapLogic server (using an Xml Writer component)
- The ATOM feed is displayed in a ATOM reader, in this case the Google Mashup Editor UI
All of this is achieved via configuration, not code. The architecture is depicted in this diagram:
The resulting web application appears like this:
For more detailed information on the implementation of this mashup, consult the companion entry on SnapLogic's blog:
- SnapLogic CTO Mike Pittaro's blog entry on the Oracle mashup
Oracle and REST
This is a simple demonstration that shows the ease of implementing integrations using RESTful techniques, especially when combined with a REST integration enabler such as SnapLogic. It is a stated goal of some of the Oracle product groups to provide RESTful APIs for access to product data. Check with the roadmap for each product to understand when these APIs will be available.
Attendees to Oracle Open World 2008 will have several sessions related to Oracle product groups and REST:
- Deploying a Web-Oriented Architecture with Oracle WebCenter, Oracle WebLogic Portal, and Oracle WebCenter Interaction
- Give Users What They Want: Web-Based Data Access and Rich Internet Applications
- No REST for the Weary: REST APIs and the Activity Stream
Oracle Internal REST Symposium
For Oracle employees, more information is available on the company intranet. I organized an internal symposium on REST amongst the product groups on July 28th, 2008. The event included speakers from Yahoo! and SnapLogic.
![]()
The agenda covered a number of RESTful topics, including:
- Explaining REST (Subbu Allamaraju of Yahoo!)
- Industry product landscape - SnapLogic (Mike Pittaro, CTO SnapLogic), and other products
- Enabling technologies - RESTlet, JSR 311, WADL, JSON marshalling
- Oracle Product efforts - presentations by various products groups on their REST efforts
Access to the recordings and slide decks can be found on the intranet here.
Resources
You may find the following links helpful:
- The hosted WLP CM REST feed of crashed automobiles
- The WLP CM REST API implementation (offered as a JSP for easy distribution, but could be a servlet)
- The hosted demo on Google Mashup Editor
- SnapLogic website.
- SnapLogic CTO Mike Pittaro's blog entry explaining the implementation
- SnapLogic CEO Chris Marino's blog entry discussing his thoughts on the REST Symposium
- REST wikipedia entry

















